The award-winning WIRED UK Podcast with James Temperton and the rest of the team. Listen every week for the an informed and entertaining rundown of latest technology, science, business and culture news. New episodes every Friday.
…
continue reading
Inhalt bereitgestellt von LessWrong. Alle Podcast-Inhalte, einschließlich Episoden, Grafiken und Podcast-Beschreibungen, werden direkt von LessWrong oder seinem Podcast-Plattformpartner hochgeladen und bereitgestellt. Wenn Sie glauben, dass jemand Ihr urheberrechtlich geschütztes Werk ohne Ihre Erlaubnis nutzt, können Sie dem hier beschriebenen Verfahren folgen https://de.player.fm/legal.
Ähnelt LessWrong (Curated & Popular)
BBC Radio 5 live’s award winning gaming podcast, discussing the world of video games and games culture.
…
continue reading
The director’s commentary track for Daring Fireball. Long digressions on Apple, technology, design, movies, and more.
…
continue reading
Hanselminutes is Fresh Air for Developers. A weekly commute-time podcast that promotes fresh technology and fresh voices. Talk and Tech for Developers, Life-long Learners, and Technologists.
…
continue reading
The power of Data is undeniable. And unharnessed - it's nothing but chaos. Making data your ally. Using it to lead with confidence and clarity. Host Jess Carter is solving problems in real-time to reveal what's possible. Helping communities and people thrive. This is Data Driven Leadership, a show brought to you by Resultant.
…
continue reading
WSJ’s Bold Names brings you conversations with the leaders of the bold-named companies featured in the pages of The Wall Street Journal. Hosts Tim Higgins and Christopher Mims speak to CEOs and business leaders in interviews that challenge conventional wisdom and take you inside the decisions being made in the C-suite and beyond.
…
continue reading
We help founders make something people want. The Y Combinator Podcast is where builders talk about building. From the earliest days of an idea to scaling a company that changes the world, YC partners and founders share real stories, lessons, and tactics from the frontlines.
…
continue reading
Android Backstage, a podcast by and for Android developers. Hosted by developers from the Android engineering team, this show covers topics of interest to Android programmers, with in-depth discussions and interviews with engineers on the Android team at Google. Subscribe to Android Developers YouTube → https://goo.gle/AndroidDevs
…
continue reading
Big tech is transforming every aspect of our world. But how, and at what cost? This season of Land of the Giants – The Disney Dilemma – focuses on Disney’s ability to weather the ups and downs of the business cycle and changing tastes and explores what has kept it successful for over 100 years. The entertainment giant has leveraged nostalgia and its intellectual property to build a beloved brand, but after an acquisition spree that included Marvel, Lucasfilm, and 20th Century Fox, can it sus ...
…
continue reading
What does it really mean to live a good life—in our politics, our faith, our work, and our relationships? On No Small Endeavor with Lee C. Camp, we explore the ideas, practices, and public debates that shape human flourishing today. Each week you’ll hear thought-provoking conversations with bestselling authors, philosophers, neuroscientists, psychologists, theologians, artists, and political leaders—people wrestling with the biggest questions of meaning and purpose in our time. Together we a ...
…
continue reading
Player FM - Podcast-App
Gehen Sie mit der App Player FM offline!
Gehen Sie mit der App Player FM offline!

))
“How Well Does RL Scale?” by Toby_Ord
Manage episode 516788581 series 3364760
Inhalt bereitgestellt von LessWrong. Alle Podcast-Inhalte, einschließlich Episoden, Grafiken und Podcast-Beschreibungen, werden direkt von LessWrong oder seinem Podcast-Plattformpartner hochgeladen und bereitgestellt. Wenn Sie glauben, dass jemand Ihr urheberrechtlich geschütztes Werk ohne Ihre Erlaubnis nutzt, können Sie dem hier beschriebenen Verfahren folgen https://de.player.fm/legal.
This is the latest in a series of essays on AI Scaling.
You can find the others on my site.
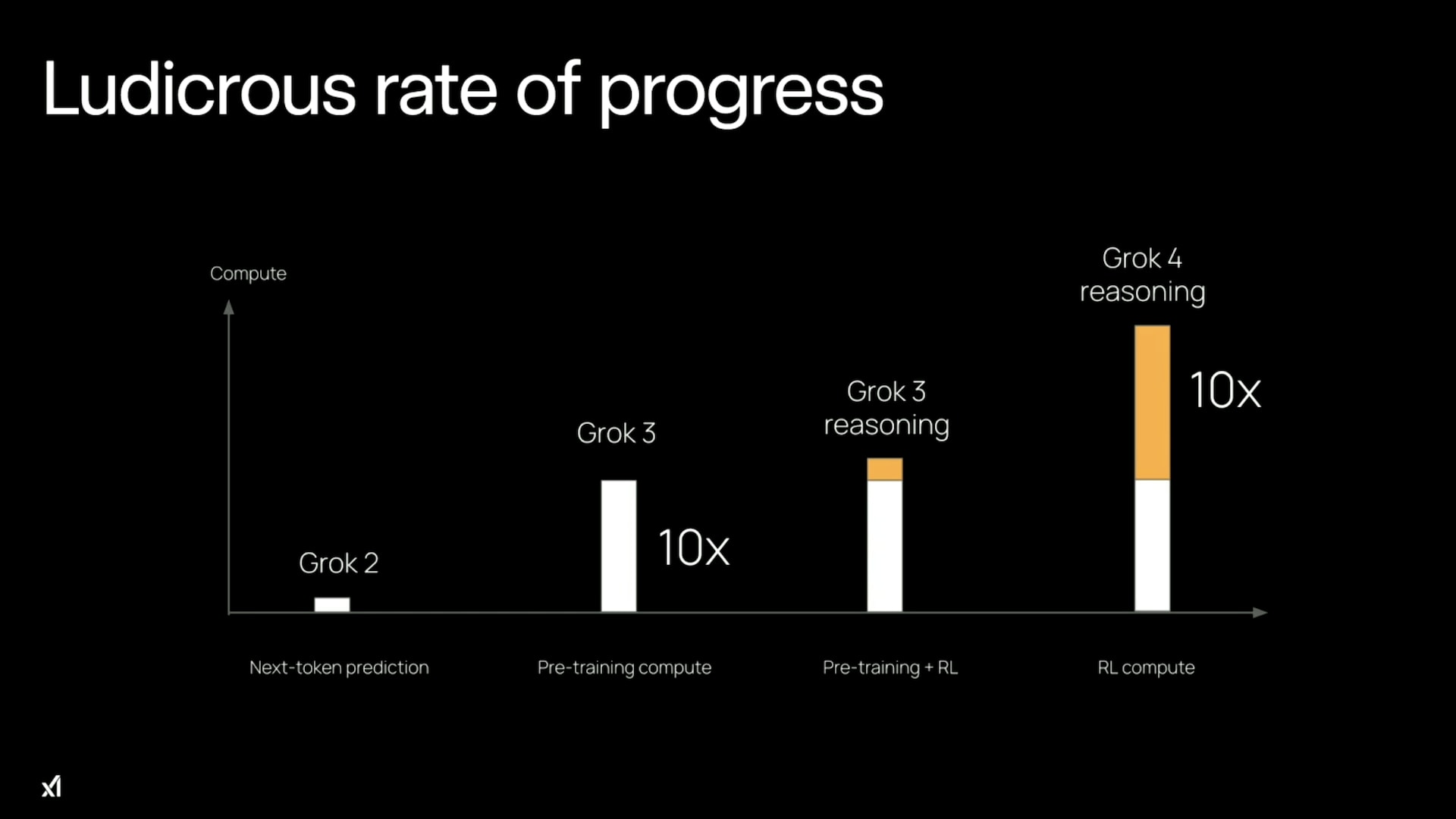
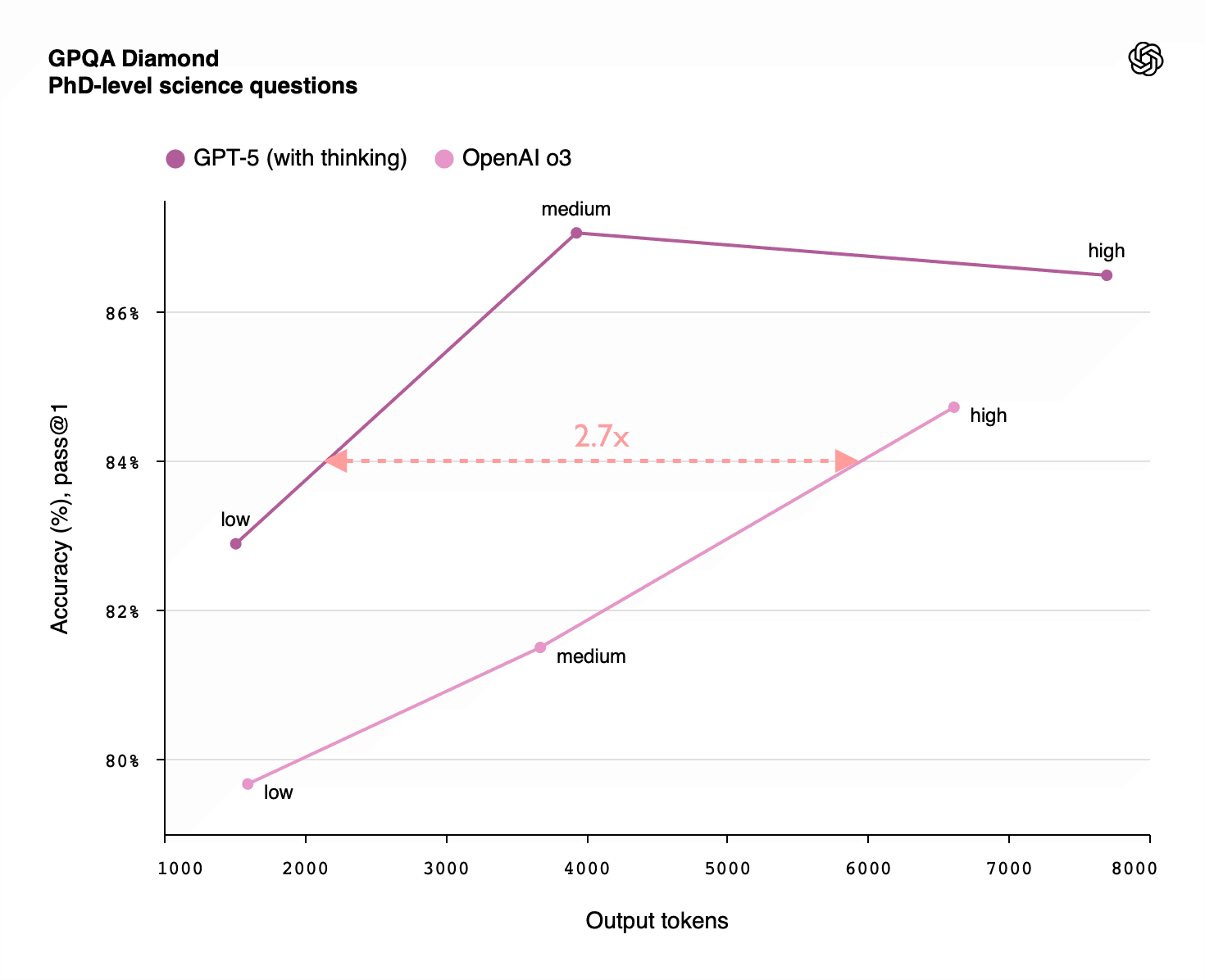
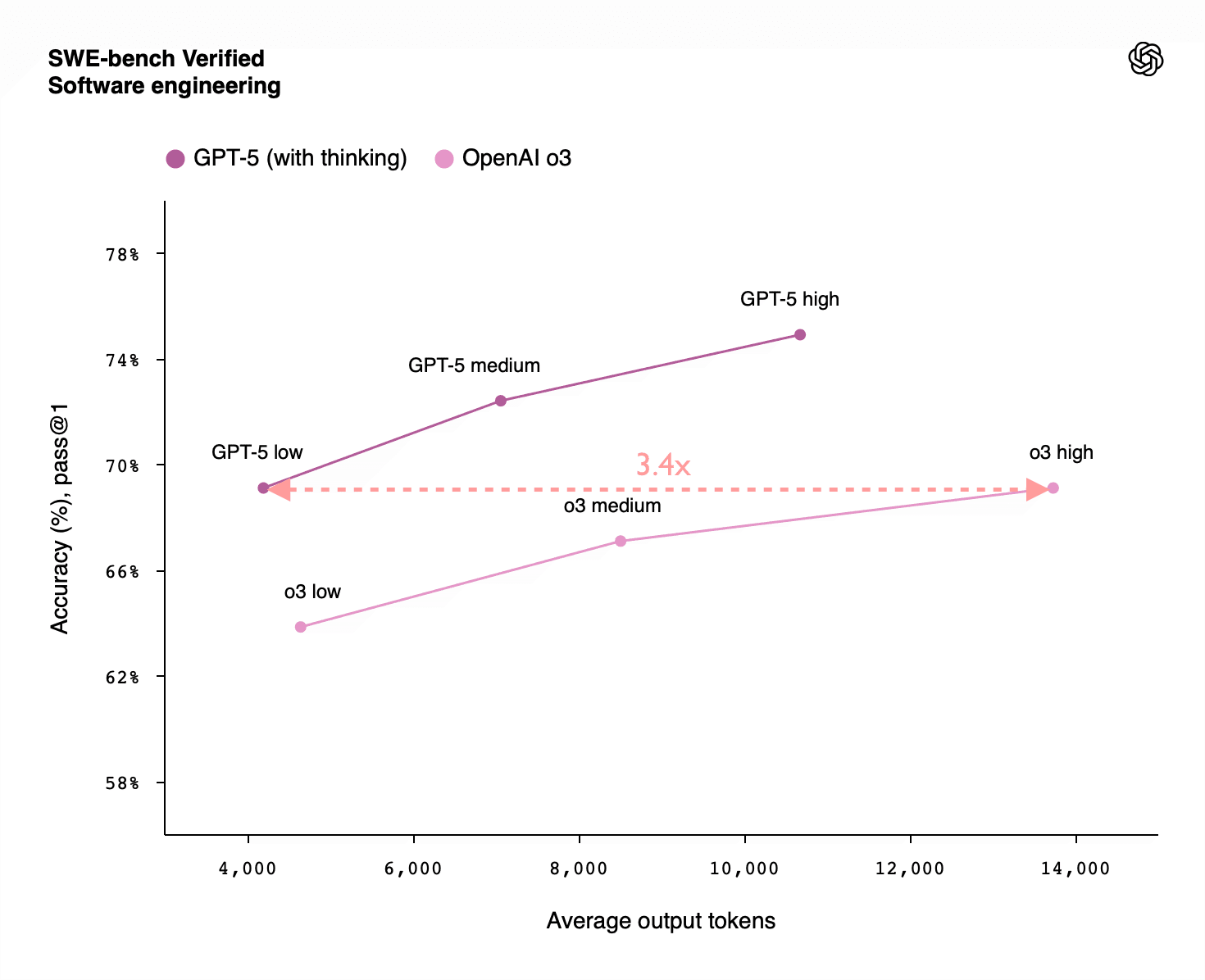
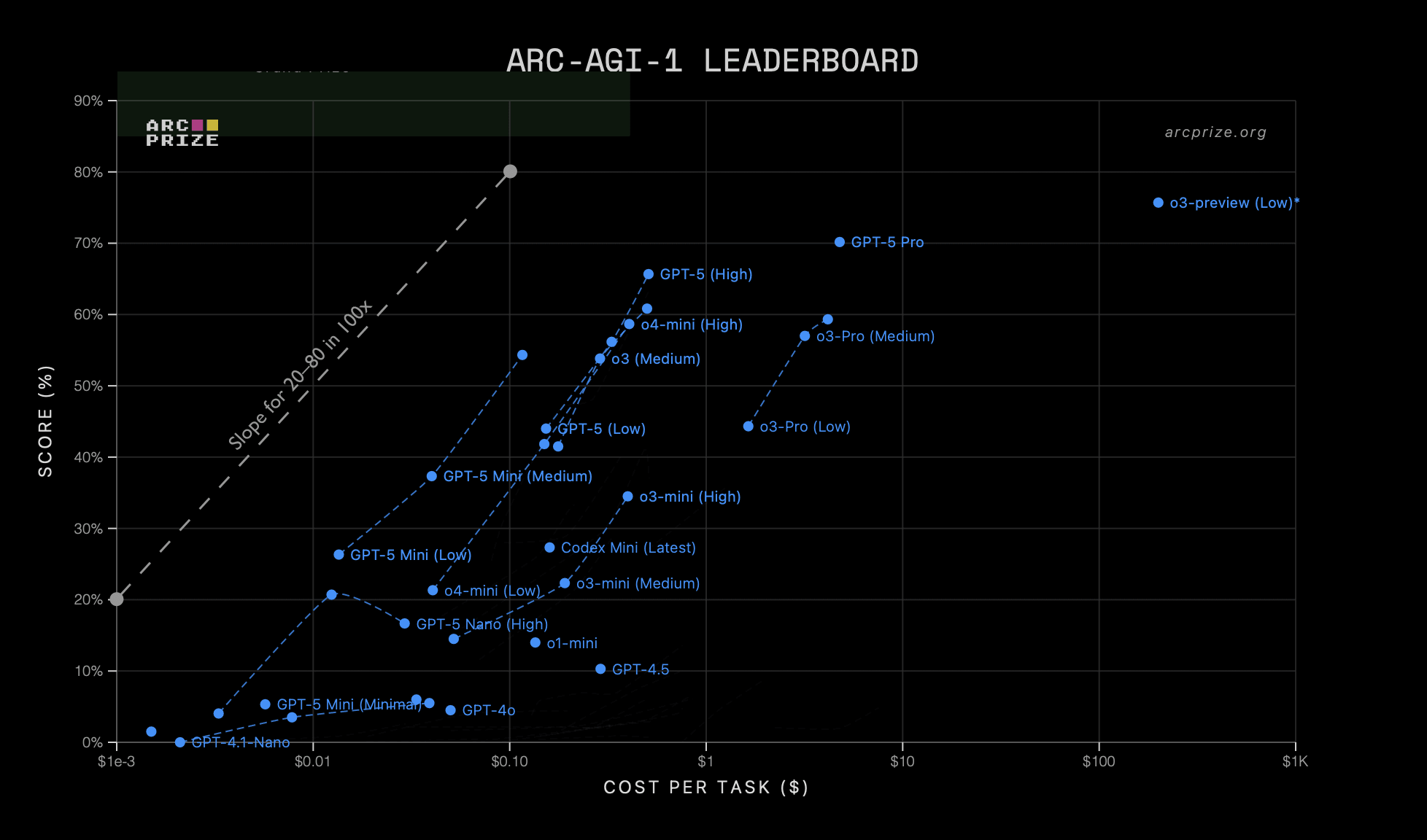
Summary: RL-training for LLMs scales surprisingly poorly. Most of its gains are from allowing LLMs to productively use longer chains of thought, allowing them to think longer about a problem. There is some improvement for a fixed length of answer, but not enough to drive AI progress. Given the scaling up of pre-training compute also stalled, we'll see less AI progress via compute scaling than you might have thought, and more of it will come from inference scaling (which has different effects on the world). That lengthens timelines and affects strategies for AI governance and safety.
The current era of improving AI capabilities using reinforcement learning (from verifiable rewards) involves two key types of scaling:
---
Outline:
(09:46) How do these compare to pre-training scaling?
(14:16) Conclusion
---
First published:
October 22nd, 2025
Source:
https://www.lesswrong.com/posts/xpj6KhDM9bJybdnEe/how-well-does-rl-scale
---
Narrated by TYPE III AUDIO.
---
…
continue reading
You can find the others on my site.
Summary: RL-training for LLMs scales surprisingly poorly. Most of its gains are from allowing LLMs to productively use longer chains of thought, allowing them to think longer about a problem. There is some improvement for a fixed length of answer, but not enough to drive AI progress. Given the scaling up of pre-training compute also stalled, we'll see less AI progress via compute scaling than you might have thought, and more of it will come from inference scaling (which has different effects on the world). That lengthens timelines and affects strategies for AI governance and safety.
The current era of improving AI capabilities using reinforcement learning (from verifiable rewards) involves two key types of scaling:
- Scaling the amount of compute used for RL during training
- Scaling [...]
---
Outline:
(09:46) How do these compare to pre-training scaling?
(14:16) Conclusion
---
First published:
October 22nd, 2025
Source:
https://www.lesswrong.com/posts/xpj6KhDM9bJybdnEe/how-well-does-rl-scale
---
Narrated by TYPE III AUDIO.
---
658 Episoden
Manage episode 516788581 series 3364760
Inhalt bereitgestellt von LessWrong. Alle Podcast-Inhalte, einschließlich Episoden, Grafiken und Podcast-Beschreibungen, werden direkt von LessWrong oder seinem Podcast-Plattformpartner hochgeladen und bereitgestellt. Wenn Sie glauben, dass jemand Ihr urheberrechtlich geschütztes Werk ohne Ihre Erlaubnis nutzt, können Sie dem hier beschriebenen Verfahren folgen https://de.player.fm/legal.
This is the latest in a series of essays on AI Scaling.
You can find the others on my site.
Summary: RL-training for LLMs scales surprisingly poorly. Most of its gains are from allowing LLMs to productively use longer chains of thought, allowing them to think longer about a problem. There is some improvement for a fixed length of answer, but not enough to drive AI progress. Given the scaling up of pre-training compute also stalled, we'll see less AI progress via compute scaling than you might have thought, and more of it will come from inference scaling (which has different effects on the world). That lengthens timelines and affects strategies for AI governance and safety.
The current era of improving AI capabilities using reinforcement learning (from verifiable rewards) involves two key types of scaling:
---
Outline:
(09:46) How do these compare to pre-training scaling?
(14:16) Conclusion
---
First published:
October 22nd, 2025
Source:
https://www.lesswrong.com/posts/xpj6KhDM9bJybdnEe/how-well-does-rl-scale
---
Narrated by TYPE III AUDIO.
---
…
continue reading
You can find the others on my site.
Summary: RL-training for LLMs scales surprisingly poorly. Most of its gains are from allowing LLMs to productively use longer chains of thought, allowing them to think longer about a problem. There is some improvement for a fixed length of answer, but not enough to drive AI progress. Given the scaling up of pre-training compute also stalled, we'll see less AI progress via compute scaling than you might have thought, and more of it will come from inference scaling (which has different effects on the world). That lengthens timelines and affects strategies for AI governance and safety.
The current era of improving AI capabilities using reinforcement learning (from verifiable rewards) involves two key types of scaling:
- Scaling the amount of compute used for RL during training
- Scaling [...]
---
Outline:
(09:46) How do these compare to pre-training scaling?
(14:16) Conclusion
---
First published:
October 22nd, 2025
Source:
https://www.lesswrong.com/posts/xpj6KhDM9bJybdnEe/how-well-does-rl-scale
---
Narrated by TYPE III AUDIO.
---
658 Episoden
Alle Folgen
×Willkommen auf Player FM!
Player FM scannt gerade das Web nach Podcasts mit hoher Qualität, die du genießen kannst. Es ist die beste Podcast-App und funktioniert auf Android, iPhone und im Web. Melde dich an, um Abos geräteübergreifend zu synchronisieren.
Ähnelt LessWrong (Curated & Popular)
The award-winning WIRED UK Podcast with James Temperton and the rest of the team. Listen every week for the an informed and entertaining rundown of latest technology, science, business and culture news. New episodes every Friday.
…
continue reading
BBC Radio 5 live’s award winning gaming podcast, discussing the world of video games and games culture.
…
continue reading
The director’s commentary track for Daring Fireball. Long digressions on Apple, technology, design, movies, and more.
…
continue reading
Hanselminutes is Fresh Air for Developers. A weekly commute-time podcast that promotes fresh technology and fresh voices. Talk and Tech for Developers, Life-long Learners, and Technologists.
…
continue reading
The power of Data is undeniable. And unharnessed - it's nothing but chaos. Making data your ally. Using it to lead with confidence and clarity. Host Jess Carter is solving problems in real-time to reveal what's possible. Helping communities and people thrive. This is Data Driven Leadership, a show brought to you by Resultant.
…
continue reading
WSJ’s Bold Names brings you conversations with the leaders of the bold-named companies featured in the pages of The Wall Street Journal. Hosts Tim Higgins and Christopher Mims speak to CEOs and business leaders in interviews that challenge conventional wisdom and take you inside the decisions being made in the C-suite and beyond.
…
continue reading
We help founders make something people want. The Y Combinator Podcast is where builders talk about building. From the earliest days of an idea to scaling a company that changes the world, YC partners and founders share real stories, lessons, and tactics from the frontlines.
…
continue reading
Android Backstage, a podcast by and for Android developers. Hosted by developers from the Android engineering team, this show covers topics of interest to Android programmers, with in-depth discussions and interviews with engineers on the Android team at Google. Subscribe to Android Developers YouTube → https://goo.gle/AndroidDevs
…
continue reading
Big tech is transforming every aspect of our world. But how, and at what cost? This season of Land of the Giants – The Disney Dilemma – focuses on Disney’s ability to weather the ups and downs of the business cycle and changing tastes and explores what has kept it successful for over 100 years. The entertainment giant has leveraged nostalgia and its intellectual property to build a beloved brand, but after an acquisition spree that included Marvel, Lucasfilm, and 20th Century Fox, can it sus ...
…
continue reading
What does it really mean to live a good life—in our politics, our faith, our work, and our relationships? On No Small Endeavor with Lee C. Camp, we explore the ideas, practices, and public debates that shape human flourishing today. Each week you’ll hear thought-provoking conversations with bestselling authors, philosophers, neuroscientists, psychologists, theologians, artists, and political leaders—people wrestling with the biggest questions of meaning and purpose in our time. Together we a ...
…
continue reading
Player FM - Podcast-App
Gehen Sie mit der App Player FM offline!
Gehen Sie mit der App Player FM offline!



